1、原始数据如图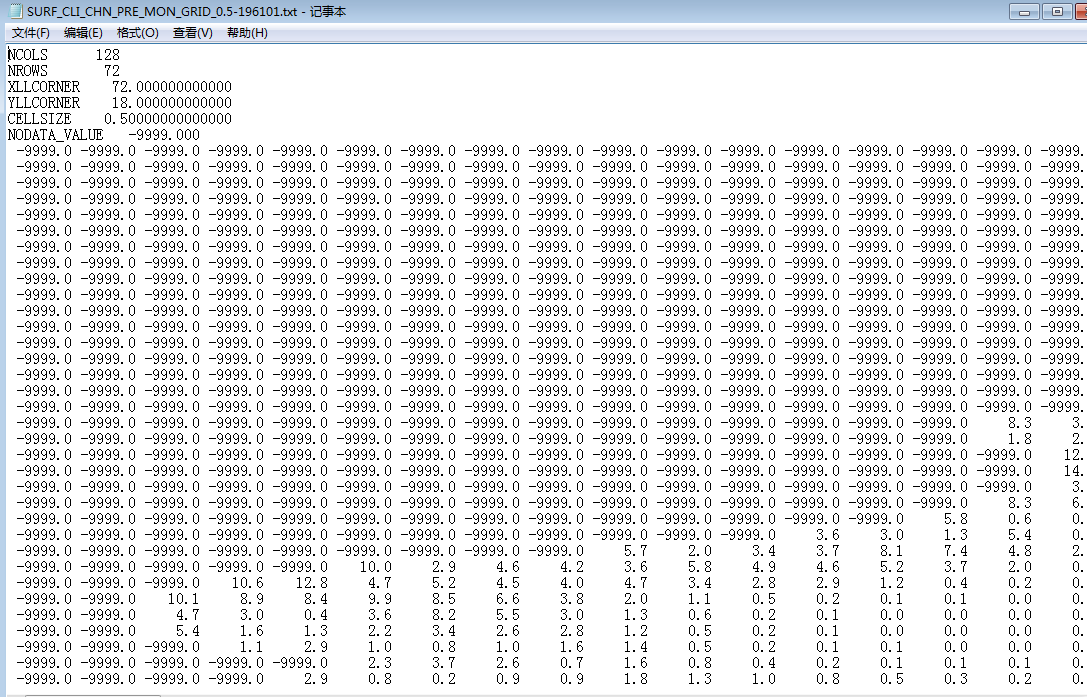 ,
,
2、将原始的气象站点数据按照地理研究区域提取出来。如图: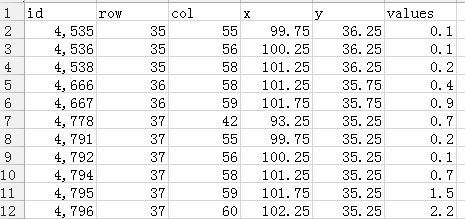
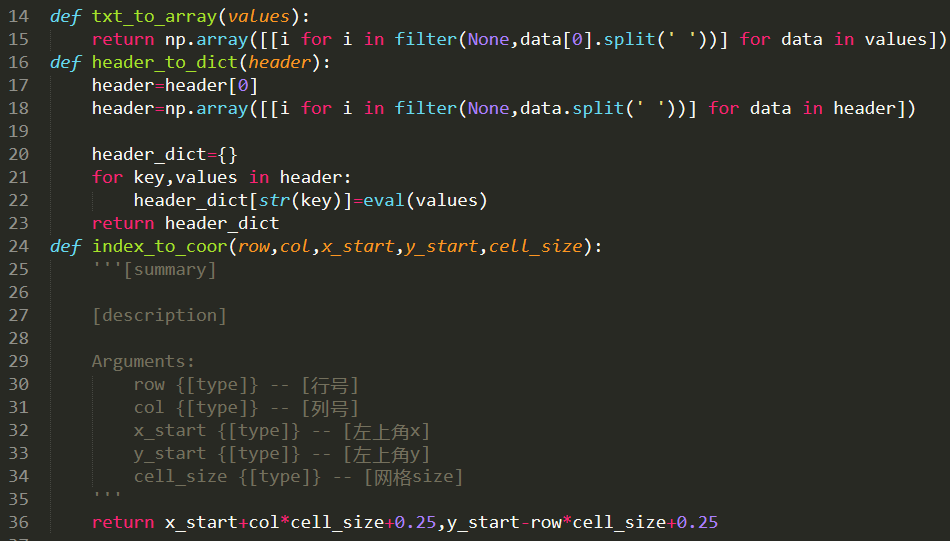
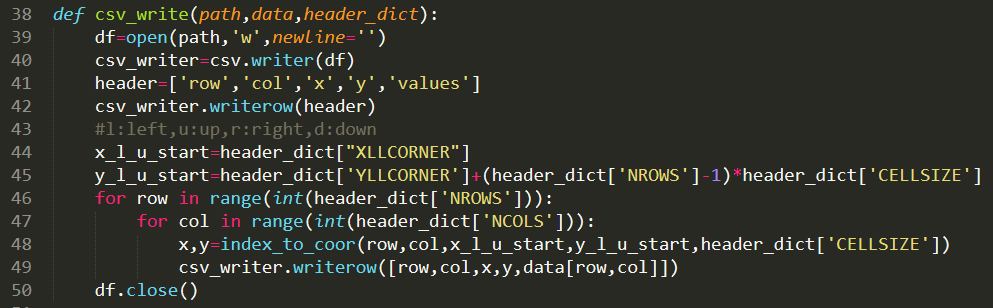
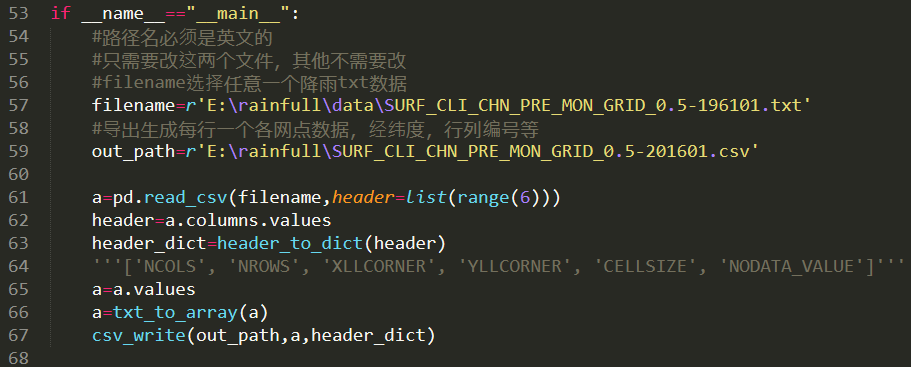
3、利用python程序进行处理,代码如下:
4、运行得到结果如下图
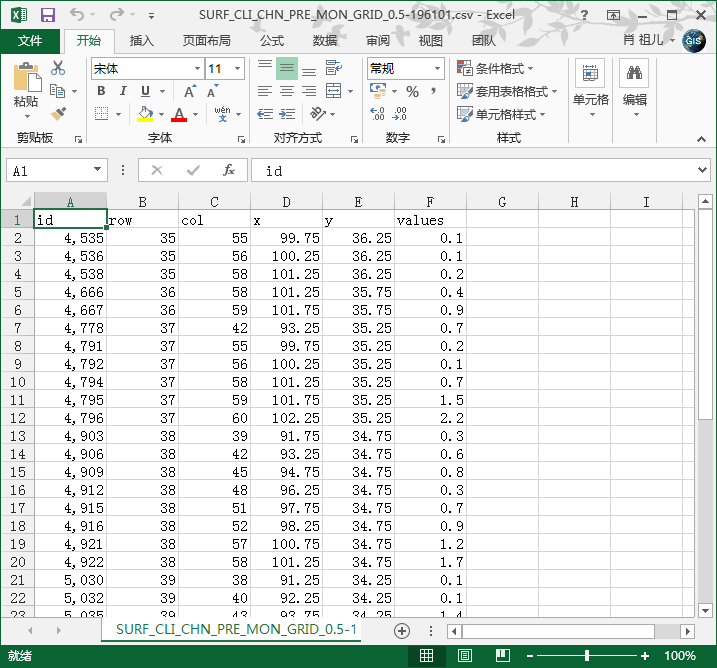
5、说明:
此步骤是将带有缺省值的原始降水数据处理成带有行列号、坐标和降水值的csv格式数据,方便后期进行降水数据的分析与使用。代码部分为开头声明的作者,使用者需声明版权。
具体代码如下:
1 import numpy 2 import csv 3 import pandas as pd 4 import numpy as np 5 6 7 def txt_to_array(values): 8 return np.array([[i for i in filter(None,data[0].split(' '))] for data in values]) 9 def header_to_dict(header):10 header=header[0]11 header=np.array([[i for i in filter(None,data.split(' '))] for data in header])12 13 header_dict={}14 for key,values in header:15 header_dict[str(key)]=eval(values)16 return header_dict17 def index_to_coor(row,col,x_start,y_start,cell_size):18 '''[summary]19 20 [description]21 22 Arguments:23 row {[type]} -- [行号]24 col {[type]} -- [列号]25 x_start {[type]} -- [左上角x]26 y_start {[type]} -- [左上角y]27 cell_size {[type]} -- [网格size]28 '''29 return x_start+col*cell_size+0.25,y_start-row*cell_size+0.2530 31 def csv_write(path,data,header_dict):32 df=open(path,'w',newline='')33 csv_writer=csv.writer(df)34 header=['row','col','x','y','values']35 csv_writer.writerow(header)36 #l:left,u:up,r:right,d:down37 x_l_u_start=header_dict["XLLCORNER"]38 y_l_u_start=header_dict['YLLCORNER']+(header_dict['NROWS']-1)*header_dict['CELLSIZE']39 for row in range(int(header_dict['NROWS'])):40 for col in range(int(header_dict['NCOLS'])):41 x,y=index_to_coor(row,col,x_l_u_start,y_l_u_start,header_dict['CELLSIZE'])42 csv_writer.writerow([row,col,x,y,data[row,col]])43 df.close()44 45 46 if __name__=="__main__":47 #路径名必须是英文的48 #只需要改这两个文件,其他不需要改49 #filename选择任意一个降雨txt数据50 filename=r'E:\rainfull\data\SURF_CLI_CHN_PRE_MON_GRID_0.5-196101.txt'51 #导出生成每行一个各网点数据,经纬度,行列编号等52 out_path=r'E:\rainfull\SURF_CLI_CHN_PRE_MON_GRID_0.5-201601.csv'53 54 a=pd.read_csv(filename,header=list(range(6)))55 header=a.columns.values56 header_dict=header_to_dict(header)57 '''['NCOLS', 'NROWS', 'XLLCORNER', 'YLLCORNER', 'CELLSIZE', 'NODATA_VALUE']'''58 a=a.values59 a=txt_to_array(a)60 csv_write(out_path,a,header_dict)